1c. Do some more work with logistic regression by hand.¶
I ran some Python/scikit-learn code to make the model pictured here: 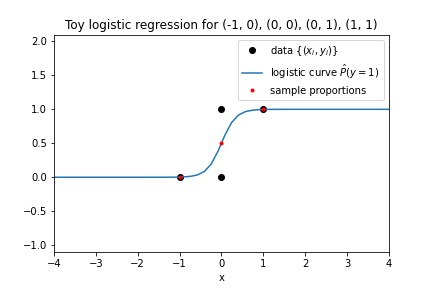
From the image and without the help of running code, match each code line from the top list with its output from the bottom list.
model.intercept_model.coef_model.predict(X)model.predict_proba(X)[:, 1]
A. array([0, 0, 0, 1]),
B. array([0.003, 0.5, 0.5, 0.997]),
C. array([5.832]),
D. array([0.])