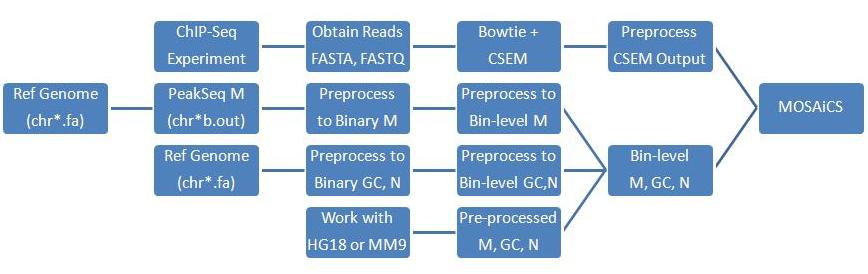
Work-flow of ChIP-Seq Analysis utilizing Multi-reads
 [Note]
[Note]
CSEM = ChIP-Seq multi-read allocation using E-M algorithm
MOSAiCS = MOdel-based one and two Sample Analysis and Inference for ChIP-Seq Data
Ref Genome = Reference genome assembly FASTA files
M = mappability score (Ref Genome -> PeakSeq M -> Binary M -> Bin-level M)
GC = GC content score (Ref Genome -> Binary GC -> Bin-level GC)
N = ambiguity score (Ref Genome -> Binary N -> Bin-level N)